
雖然NVIDIA甫在GTC 2024公布眾所矚目的全新Blackwell架構,但畢竟Blackwell仍要待到2024年下半年才會開始出貨,故目前最新的NVIDIA AI GPU加速產品為採用美光HBM3e記憶體的NVIDIA H200 Tensor Core GPU;NVIDIA公布全新的MLPerf測試成績,基於Hopper架構的H100借助TensorRT-LLM軟體突破MLPerf的生成式AI測試項突破原本的性能上限,於GPT-J LLM推論性能較6個月前提升近3倍,而陸續出貨的H200 GPU則透過容量、頻寬提升的HBM3e記憶體與更彈性的散熱,一舉刷新多項MLPerf的紀錄。

▲包括大型語言模型、圖像生成與推薦系統都是NVIDIA推論系統的熱門應用領域
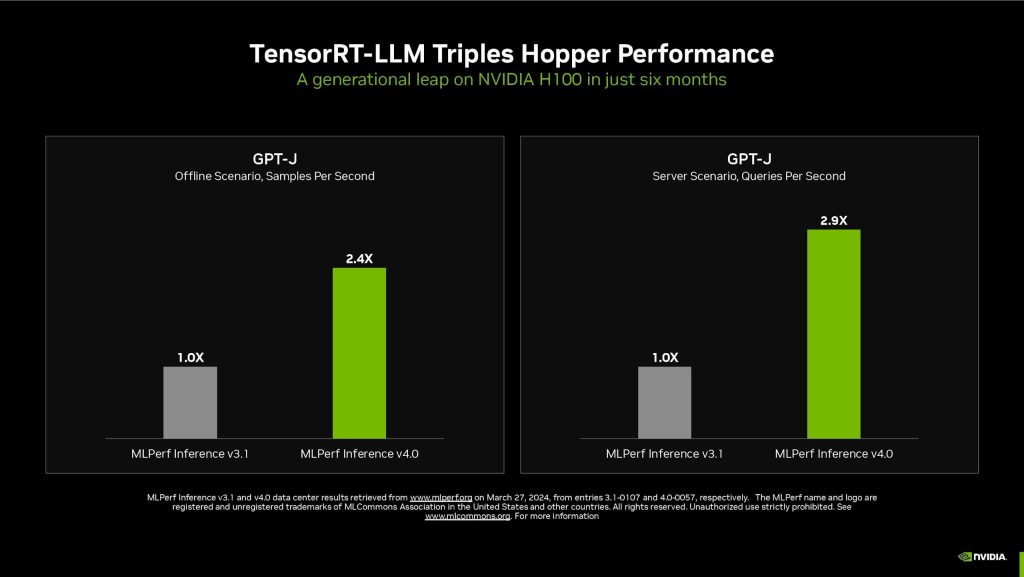
▲相較去年9月的結果,NVIDIA透過TensorRT-LLM使GPT-J推論提升將近3倍性能

▲系統商的客製化散熱方案能使Hopper性能獲得14%成長
MLPerf在v4.0版本加入兩項生成式AI測試項,使用Llama 2當中70B參數的最大規模模型版本作為基準,此模型相較2023年9月的GPT-J LLM規模大了10倍以上,對記憶體容量與性能也有更高的要求;NVIDIA透過強化Hpper架構的記憶體的H200 GPU進行測試,搭配TensorRT-LLM,每秒可產生3.1萬個Token,是目前MLPerf的Llama 2測試基準的紀錄,此外透過客製化的散熱方案,使系統提升14%的性能增長,當前許多系統商也陸續將客製化散熱設計導入NVDIA MGX設計,進一步提升Hopper架構的性能。
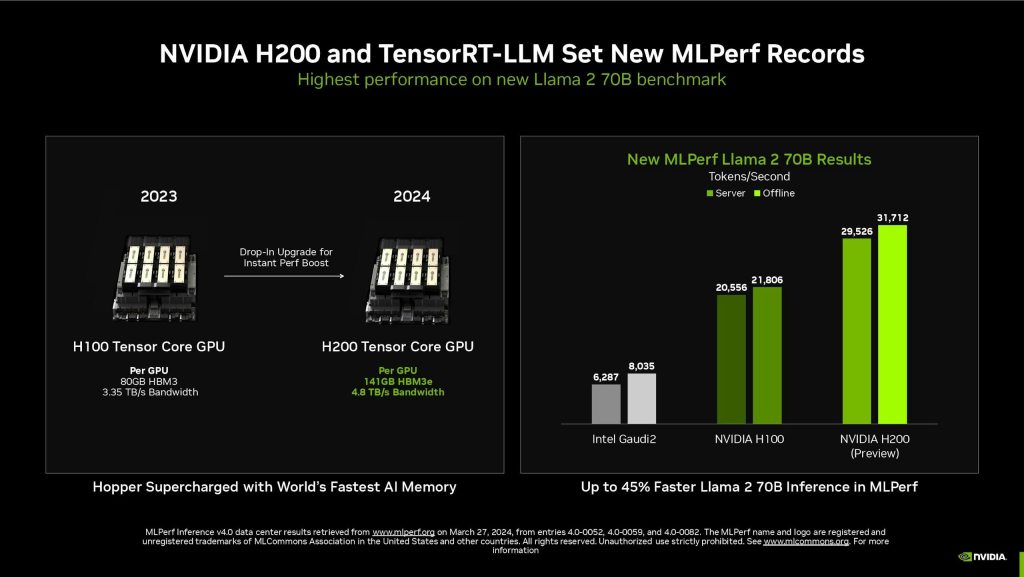
▲H200藉由記憶體容量擴增與傳輸性能提升,不僅提升Llama 2 70B的推論性能且足以在單一GPU進行推論

▲近20家系統商與雲端服務商將推出搭載H200的系統與服務
NVIDIA的H200 GPU將由近20家領先的系統商與雲端服務商推出,H200搭載高達141GB、頻寬達4.8TB/s的HBM3e記憶體,容量較H100提高76%容量、傳輸性能提升43%,同時仍可相容既有的H100系統設計;透過記憶體容量的提升,單一個H200 GPU即足以執行Liama 2 70B的模型,進而簡化與加速推論。
對於單一系統記憶體更為苛求的客戶,NVIDIA則提供NVIDIA GH200 Superchips平台,在單一超級晶片提供高達624GB的高速記憶體,其中包含144GB的HBM3e記憶體,在超級晶片整合兼具效能與能耗的Grace GPU與H200 GPU,彼此之間透過NVLink-C2C高速溝通,對於如推薦系統等記憶體密集的MLPerf測試提供出色的效益。

▲NVIDIA的GPU加速運算能因應市場所有AI領域的運算需求與支援廣泛模型
做為首家自2020年10月即開始遞交MLPerf測試結果的平台,NVIDIA與合作夥伴屢屢刷新MLPerf的紀錄,霸佔生成式AI、推薦系統、自然語言模型、語音與電腦視覺領域的測試成績龍頭,且不光僅是透過更新硬體刷新成績,透過軟體更新後也能使既有硬體獲得飛躍的性能表現。
NVIDIA突破性能上限的關鍵是透過三項創新技術,包括首度在NVIDIA A100 Tensor Core GPU導入的結構稀疏化技術,該項技術能使H100執行Llama 2推論速度提升33%;第二項創新技術式則是稱為Puring(修剪)的吞吐量提升技術,藉此方式能簡化如大型語言模型等AI模型,使H100的推論速度提升40%;最後一項創新技術則是稱為DeepCache的最佳化技術,可減少執行如Stable Diffusion XL模型的運算需求,使效能提升76%。
▲NVIDIA強調其測試結果皆公開透明,同時相關資源也採取開源供開發者存取
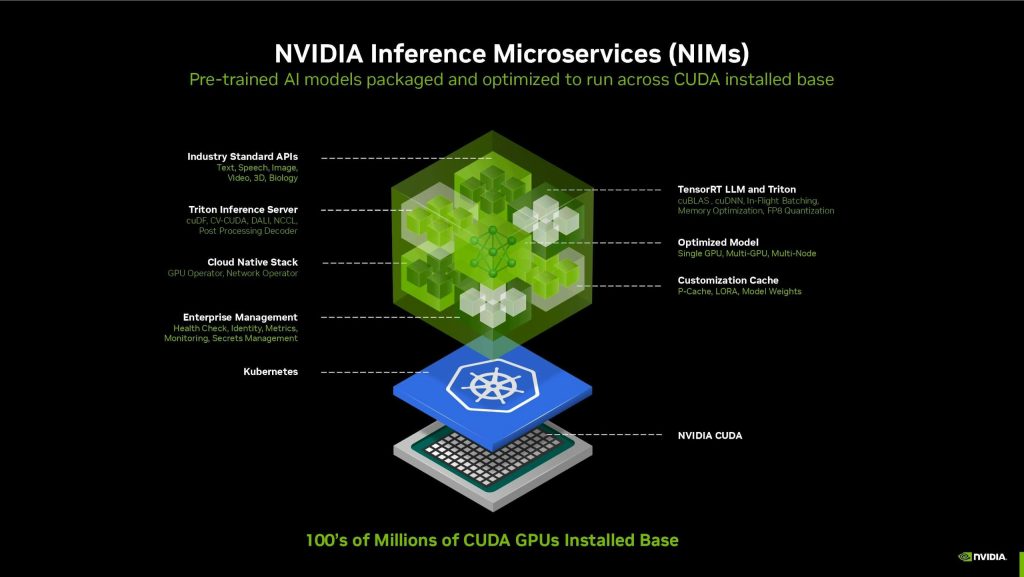
▲NIM推論微服務將助生成式AI應用更易開發與客製化
NVIDIA強調其測試結果是公開且透明,相關資源也採取開源,且不僅由NVIDIA遞交結果,包括採用NVIDIA技術的合作夥伴如華碩、Cisco、Dell、富士通、技嘉、Google、HPE慧與、聯想、微軟Azure、甲骨文Oricle、QCT(廣達/雲達)、Supermicro美超微、VMware與緯穎都進行測試並上繳結果,橫跨系統供應、雲端服務等領域,同時測試的結果也都能在MLPerf資料庫找到,並可看到透過不斷進化的NGC、NVIDIA GPU Software Hub、1包括NVDIA NIM微服務的NVIDIA AI Enterprise等持續提升的效能。

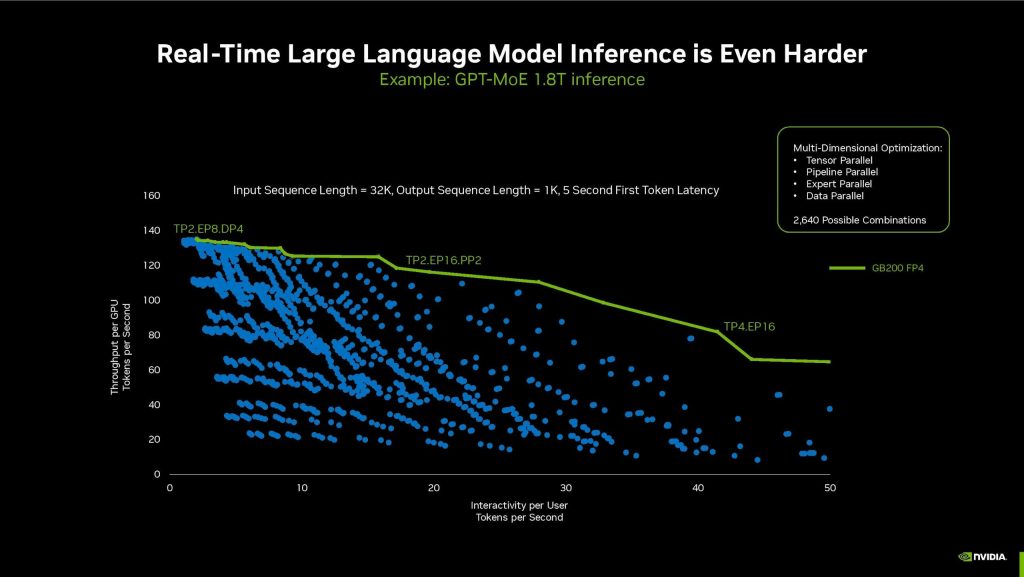
▲大型語言模型將邁入兆級參數世代,Blackwell架構則是因應參數不斷擴張的新GPU架構
▲Blackwell為提升即時推論性能支援FP4
隨著生成式AI技術與應用如火如荼的發展,接下來除了更具效益的最佳化模型外,具理解與能產生更複雜內容的兆級數據參數模型也很快就要出現,NVIDIA於GTC 2024公布、預計2024年內推出的Blackwell架構即是因應兆數參數需求,不僅效能有顯著的提升,也具備更大的規模化與記憶體容量,還支援FP4浮點,將解決未來兆級參數生成式AI模型的需求。


















暂无评论内容