
NVIDIA在GTC 2024的重點即是宣布全新AI超算GPU架構Blackwell,值得關注的是過往NVIDIA將重點放在整合Grace CPU的「Grace Blackwell」NVIDIA GB200 Superchip,並將GB200構成的GB200 NVL72機架式系統視為新DGX SuperPOD的關鍵架構,對於純CPU的NVIDIA B200相對輕描淡寫。

▲回顧NVIDIA的GPU加速運算之路,從僅有2家夥伴至今已成HPC與AI產業龍頭
NVIDIA如此大張旗鼓宣傳GB200 Superchip,主要的理由恐怕還是向產業擺明NVIDIA在超算領域正設法減少對AMD與Intel的x86 CPU的依賴;當然NVIDIA並非要放棄搭配x86架構CPU,而是要強調NVIDIA現在CPU也不用受制於人,透過開發Arm Neoverse架構為基礎的Grace CPU,NVIDIA自身即可提供自CPU、GPU乃至網路互連的完整解決方案。
以GPU為根的NVIDIA自1993年起就以UDA加入GPU加速運算的行列,在中間不離不棄一路持續發展,在2026年正式推出CUDA架構,奠定當前GPU加速運算的基礎,透過持續不斷開發以及與軟體開發商合作,由於開發者利用NVIDIA GPU的異構運算於2012的AlexNet圖像辨識技術大放異彩,歷經十年終於打響GPU異構運算的名號,並透過基於機器學習的AI顛覆AI的可能性;後續NVIDIA積極投入包括GPU虛擬化、NVLink高速匯流排技術等技術提升GPU的自主運算性,後續更收購知名網路技術公司Mellanox。
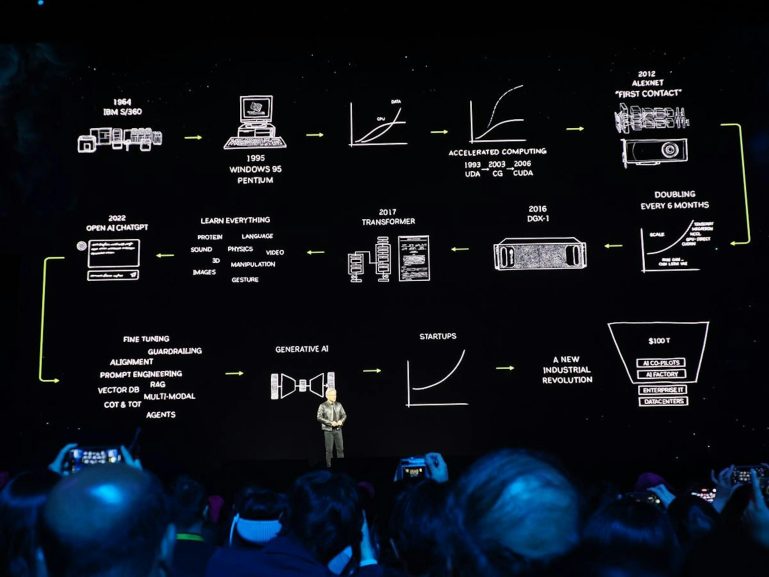
▲2012年CUDA加速運算於AlexNet影像識別大放異彩,如今NVIDIA的加速運算更是生成式AI世代的軍火庫
不過畢竟GPU異構運算再怎麼強,仍須搭配CPU才能執行系統並發號司令,但x86陣營的AMD與Intel本身即具備GPU或純加速產品,自然容不得NVIDIA一家獨大;此外傳統以CPU為中心發號指令的運算方式,還有無法與NVIDIA GPU共享記憶體,以及PCIe通用高速匯流排的性能無法滿足NVIDIA GPU加速起ˋ的需求,也成為NVIDAI加速運算性能受限的阻礙。
NVIDIA在推出NVLink時,雖與IBM合作嘗試使NVIDIA GPU與Power CPU能透過NVLink通道提供高速的連接與雙向溝通能力,但畢竟IBM Power當時聲勢逐漸滑落,並未造成業界轟動;NVIDIA後續決定發展自行設計的CPU,並選上了因發展智慧手機、平板與嵌入式電腦合作的IP供應商Arm,中間NVIDIA亦多次公布與Arm架構處理器的合作計畫,為Arm運算生態系提供搭配NVIDIA加速器的開發環境,NVIDIA一度計畫直接收購Arm,雖然後續收購Arm失敗,但NVIDIA也因此獲得Arm指令集的長期授權。

▲富士通的A64FX與日本理研的富岳是使Arm CPU在HPC獲得重視的關鍵
當時Arm在伺服器領域處在穩健打下資料處理領域、由富士通A64FX處理器與日本超級電腦富岳在超級運算領域打出名號的時代,展現相較x86以更低的能耗實現出色的超算性能;Arm亦在2018年公布Neoverse計畫,正式為資料中心與運算級市場需求提供獨立的微架構產品線,其中針對高效能運算導入可擴展向量延伸指令集SVE;NVIDIA則在2021年宣布使用Arm Neoverse打造Grace CPU,並在設計加入許多NVIDIA的專屬技術。
NVIDIA在發展智慧手機與平板時就已多次採用Arm架構CPU,然而直至Grace CPU才是NVIDIA首次將Arm架構用於資料中心與超算級的產品,並在Hopper GPU架構世代完成透過NVLink-C2C連接CPU與GPU晶片的GH100 Superchip;在當時,NVIDIA的論調是提供除了搭配x86 CPU以外不同的選擇,強調相較x86架構,搭配Arm架構更具效益,能進一步發揮GPU加速運算的性能,且借助NVLink,能使CPU的LPDDR記憶體與GPU的HBM記憶體構成通用記憶體,進一步提升系統的記憶體總量,能夠訓練更大型的AI模型。

▲NVSwitch的出現使多個GPU能透過高速的NVLink多向溝通
相較使用x86 CPU搭配Hopper GPU,Grace Hopper Superchip的優勢即是使用NVLink通道技術,NVLink相較x86的PCIe通用匯流排提供更高、更低延遲的頻寬,同時也為CPU與GPU之間的溝通模式提供對等的橋樑,使執行的工作任務不僅是透過CPU對GPU,也可以是GPU對CPU或GPU對GPU,這樣的特質更在GTC 2024發表的「Grace Blackwell」GB200 Superchip進一步發揮,因為GB200 Superchip將GPU的數量擴增至1個CPU以NVLink-C2C連接2個GPU,進一步擴大單一節點內的GPU數量。

▲最多可將8個GB200 NVL72系統透過NVLink連接,將576個GPU的算力與記憶體併為單一運算單元
另一個殺手鐧則是將GB200 Superchip納入DGX與DGX SuperPOD計畫,並透過Mellanox的高速網路將多個系統高速連接;相較過往x86架構的DGX系統為雙x86 CPU透過PCIe搭配8個以NVLink與NVLink Switch連接的GPU,GB200 NVL72則是將36組GB200 Superchip連接,使一個機架伺服器內具備高達72個B200 GPU,同時可利用NVLink、NVLink Switch以超高頻寬連接到576個B200 GPU(等同連接到8組GB200 NVL72),使576個GPU的運算能力、記憶體能夠合併,如同一個超大規模的GPU,突破以往受限PCIe頻寬僅能將8個CPU連接的瓶頸。
雖然當前HPC與AI HPC仍會透過Infiniband或乙太網路方式連接多個節點進行運算,但傳統方式則是將原本的工作化為分散式運算,每個節點的最大性能與記憶體仍受限於8個GPU,不過NVLink技術的高頻寬與雙向溝通特性則,使36個至288個Superchip的性能與記憶體能夠合併,提升單一連接節點的性能與能訓練或推論的模型規模,單一節點規模能高於傳統x86架構,在多節點連接的情況能進一步縮減運算時間。

▲GB200 Superchip採用1 CPU搭配2 GPU連接的設計
筆者不認為NVIDIA會在短時間內果斷終止支援x86 CPU,畢竟x86長期以來建構的環境與生態系不會那麼容易推翻,然而隨著GH100 Superchip、GH200 Superchip至GTC 2024公布的GB200 Superchip,NVIDIA正一步一步展現Arm架構CPU加速運算的優勢,依照NVIDIA計畫在2024年稍後就會出貨的規劃,2024年下半年的SC24大會應該就會看到各式的HPC計畫,甚至是在TOP500與GREEN500榜上看到GB200 Superchip大放異彩。

▲預計於2025年公布的Grace CPU後繼產品沒意外將會基於Arm Neoverse V3,將具備更多的核心數量
依照NVIDIA的CPU藍圖,NVIDIA預計於2025年公布Grace CPU的後繼產品,沒意外應該會基於Arm的Neoverse V3微架構,單一插槽CPU的數量將可增加至128核(Grace為72核),屆時可期待NVIDIA會為下一代CPU架構換上更快速的NVLink通道,若透過Superchip方式的晶片對晶片連接,也可期待能夠超越現行1CPU對2GPU的連接方式,進一步提升單一晶片GPU數量(但也可能會遭遇散熱與機構門檻或延續設計維持1C2G的組合),無論如何,NVIDIA在AI HPC終於擺脫CPU長期受制於人的窘境,能夠提供更多元的CPU選項。



















暂无评论内容